
As a software developer I want to be able to designate certain code to run inside the GPU so it can execute in parallel. Specifically this post demonstrates how to use Python 3.9 to run code on a GPU using a MacBook Pro with the Apple M1 Pro chip.
Tasks suited to a GPU are things like:
- summarizing values in an array (map / reduce)
- matrix multiplication, array operations
- image processing (images are arrays of pixels)
- machine learning which uses a combination of the above
To use the GPU I’ve chosen to render the Mandelbrot set. This post will also compare the performance on my MacBook Pro’s CPU vs GPU. Complete code for this project is available on github so you can try it yourself.
Writing Code To Run on the GPU:
In Python running code through the GPU is not a native feature. A popular library for this is TensorFlow 2.14 and as of October 2023 it works with the MacBook Pro M1 GPU hardware. Even though TensorFlow is designed for machine learning it offers some basic array manipulation functions that take advantage of GPU parallelization. To make the GPU work you need to install the TensorFlow-Metal package provided by Apple. Without that you are stuck in CPU land only, even with the TensorFlow package.
Programming in TensorFlow (and GPU libraries in general) requires thinking a bit differently vs conventional “procedural logic”. Instead of working on one unit at a time, TensorFlow works on all elements at once. Lists of data need to be kept in special Tensor objects (which accept numpy arrays as inputs). Operations like add, subtract, and multiply are overloaded on Tensors. Behind the scenes when you add/subtract/multiply Tensors it breaks up the data into smaller chunks and the work is farmed out to the GPUs in parallel. There is overhead to do this though, and the CPU bears the brunt of that. If your data set is small, the GPU approach will actually run slower. As the data set grows the GPU will eventually prove to be much more efficient and make tasks possible that were previously unfeasible with CPU only.
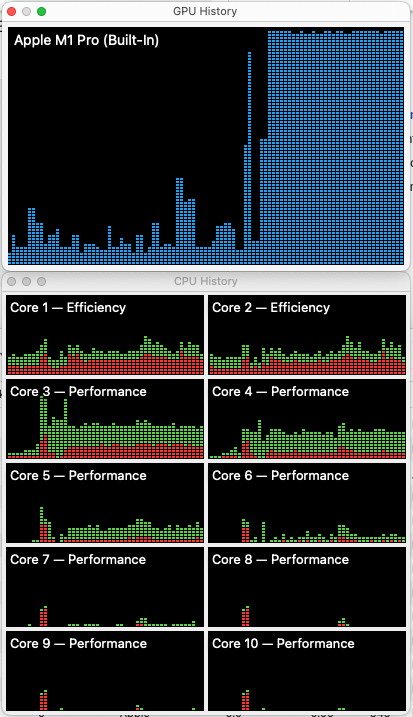
How do you know your GPU is being used?
To view your CPU and GPU usage, Open Activity Monitor, then Window -> GPU History (command 4), and then Window -> CPU History (command 3).
Run the script in step 4 of the TensorFlow-Metal instructions which fires up a bunch of Tensors and builds a basic machine learning model using test data.
In your GPU history window you should see it maxing out like so:
The Code for Mandelbrot:
The Mandelbrot set is a curious mathematical discovery from 1978. The wiki article has a great description of how it works. Basically it involves checking every point in a cartesian coordinate system to see if the value of that point is stable or diverges to infinity when fed into a “simple” equation. It happens to involve complex numbers (which have an imaginary component, and the Y values supply that portion) but Python code handles that just fine. What you get when you graph it is a beautiful / spooky image that is fractal in nature. You can keep zooming in on certain parts of it and it will reveal fractal representations of the larger view buried in the smaller view going down as far as a computer can take it.
Full view of the Mandelbrot set, generated by the code in this project:

Here is the naive “procedural” way to build the Mandelbrot set. Note that it calculates each pixel one by one.
def mandelbrot_score(self, c: complex, max_iterations: int) -> float:
"""
Computes the mandelbrot score for a given complex number provided.
Each pixel in the mandelbrot grid has a c value determined by x + 1j*y (1j is notation for sqrt(-1))
:param c: the complex number to test
:param max_iterations: how many times to crunch the z value (z ** 2 + c)
:return: 1 if the c value is stable, or a value 0 >= x > 1 that tells how quickly it diverged
(lower means it diverged faster).
"""
z = 0
for i in range(max_iterations):
z = z ** 2 + c
if abs(z) > 4:
# after it gets past abs > 4, assume it is going to infinity
# return how soon it started spiking relative to max_iterations
return i / max_iterations
# c value is stable
return 1
# below is a simplified version of the logic used in the repo's MandelbrotCPUBasic class:
# setup a numpy array grid of pixels
pixels = np.zeros((500, 500))
# compute the divergence value for each pixel
for y in range(500):
for x in range(500):
# compute the 'constant' for this pixel
c = x + 1j*y
# get the divergence score for this pixel
score = mandelbrot_score(c, 50)
# save the score in the pixel grid
pixels[y][x] = score
Here is the TensorFlow 2.x way to do it. Note that it operates on all values at once in the first line of the tensor_flow_step function, and returns the input values back to the calling loop.
def tensor_flow_step(self, c_vals_, z_vals_, divergence_scores_):
"""
The processing step for compute_mandelbrot_tensor_flow(),
computes all pixels at once.
:param c_vals_: array of complex values for each coordinate
:param z_vals_: z value of each coordinate, starts at 0 and is recomputed each step
:param divergence_scores_: the number of iterations taken before divergence for each pixel
:return: the updated inputs
"""
z_vals_ = z_vals_*z_vals_ + c_vals_
# find z-values that have not diverged, and increment those elements only
not_diverged = tf.abs(z_vals_) < 4
divergence_scores_ = tf.add(divergence_scores_, tf.cast(not_diverged, tf.float32))
return c_vals_, z_vals_, divergence_scores_
def compute(self, device='/GPU:0'):
"""
Computes the mandelbrot set using TensorFlow
:return: array of pixels, value is divergence score 0 - 255
"""
with tf.device(device):
# build x and y grids
y_grid, x_grid = np.mgrid[self.Y_START:self.Y_END:self.Y_STEP, self.X_START:self.X_END:self.X_STEP]
# compute all the constants for each pixel, and load into a tensor
pixel_constants = x_grid + 1j*y_grid
c_vals = tf.constant(pixel_constants.astype(np.complex64))
# setup a tensor grid of pixel values initialized at zero
# this will get loaded with the divergence score for each pixel
z_vals = tf.zeros_like(c_vals)
# store the number of iterations taken before divergence for each pixel
divergence_scores = tf.Variable(tf.zeros_like(c_vals, tf.float32))
# process each pixel simultaneously using tensor flow
for n in range(self.MANDELBROT_MAX_ITERATIONS):
c_vals, z_vals, divergence_scores = self.tensor_flow_step(c_vals, z_vals, divergence_scores)
self.console_progress(n, self.MANDELBROT_MAX_ITERATIONS - 1)
# normalize score values to a 0 - 255 value
pixels_tf = np.array(divergence_scores)
pixels_tf = 255 * pixels_tf / self.MANDELBROT_MAX_ITERATIONS
return pixels_tf
Results:
Here are the results of generating Mandelbrot images of varying sizes with TensorFlow using the CPU vs the GPU. Note the TensorFlow code is exactly the same, I just forced it to use CPU/GPU using the with tf.device() method.

Between TensorFlow GPU and CPU, we can see they are about the same until 5000 x 5000. Then at 10000 x 10000 the GPU takes a small lead. At 15000 x 15000 the GPU is almost twice as fast! This shows how the marshalling of resources from the CPU to the GPU adds overhead, but once the size of the data set is large enough the data processing aspect of the task out weights the extra cost of using the GPU.
Details about these results:
- Date: 10/29/2023
- MacBook Pro (16-inch, 2021)
- Chip: Apple M1 Pro
- Memory: 16GB
- macOS 12.7
- Python 3.9.9
- numpy 1.24.3
- tensorflow 2.14.0
- tensorflow-metal 1.1.0
| Alg / Device Type | Image Size | Time (seconds) |
|---|---|---|
| CPU Basic | 500×500 | 0.484236 |
| CPU Basic | 2500×2500 | 12.377721 |
| CPU Basic | 5000×5000 | 47.234169 |
| TensorFlow GPU | 500×500 | 0.372497 |
| TensorFlow GPU | 2500×2500 | 2.682249 |
| TensorFlow GPU | 5000×5000 | 13.176994 |
| TensorFlow GPU | 10000×10000 | 42.316472 |
| TensorFlow GPU | 15000×15000 | 170.987643 |
| TensorFlow CPU | 500×500 | 0.265922 |
| TensorFlow CPU | 2500×2500 | 2.552139 |
| TensorFlow CPU | 5000×5000 | 12.820812 |
| TensorFlow CPU | 10000×10000 | 46.460504 |
| TensorFlow CPU | 15000×15000 | 328.967006 |
Note: with the CPU Basic algorithm, I gave up after 5000 x 5000 because the 10000 x 10000 image was going super low and the point was well proven that TensorFlow’s implementation is much faster.
Curious how it will work on your hardware? Why not give it a try? Code for this project is available on github.
Other thoughts about running Python code on the GPU:
Another project worth mentioning is PyOpenCL. It wraps OpenCL which is a framework for writing functions that execute against different devices (including GPUs). OpenCL requires a compatible driver provided by the GPU manufacturer in order to work (think AMD, Nvidia, Intel).
I actually tried getting PyOpenCL working on my Mac, but it turns out OpenCL is no longer supported by Apple. I also came across references to CUDA which is like OpenCL, a bit more mature, except it is for Nvidia GPUs only. If you happen to have an Nvidia graphics card you could try using PyCUDA.
CUDA and OpenCL are to GPU parallel processing as DirectX and OpenGL are to doing graphics. CUDA like DirectX is proprietary but very powerful, while OpenCL and OpenGL are “open” in nature but lack certain built in features. Unfortunately on MacBook Pros with M1 chips, neither of those are options. TensorFlow was the only option I could see as of October 2023. There is a lot of out dated information online about using PyOpenCL on Mac, but it was all a dead end when I tried to get it running.
Inspiration / sources for this post:
- https://people.duke.edu/~ccc14/sta-663/CUDAPython.html – example of drawing the Mandelbrot set using CUDA.
- https://realpython.com/mandelbrot-set-python/ – complete tutorial on drawing the Mandelbrot set in Python, including colorization, and zooming into the spiral arms.
- https://dzone.com/articles/mandelbrot-set-in-tensorflow – an example using TensorFlow.
One Response to How To Make Python Code Run on the GPU