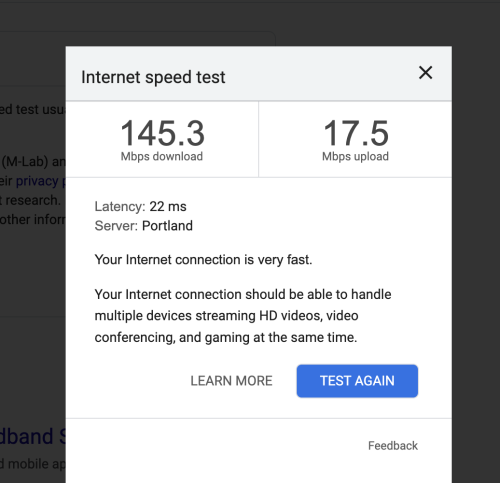
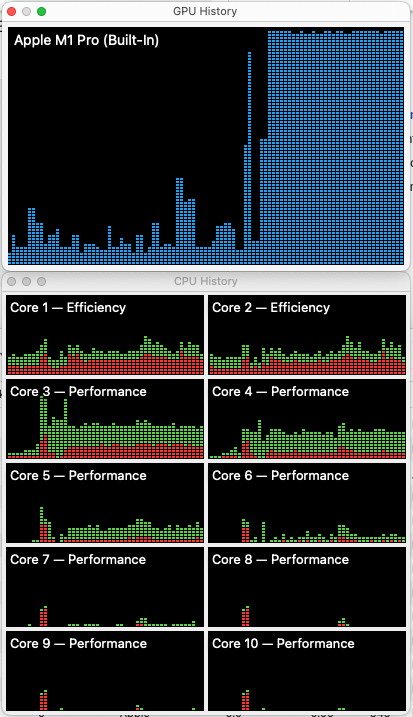
Here are my setup notes for configuring a new 16″ MacBook Pro M4 Pro in 2026 using MacOS Tahoe.
Each time I setup a new laptop I make a copy of my notes file from last time. As I work through it I make changes as needed to keep it up to date. My goal with this round was to install fewer libraries and programs (via brew, etc) and use Docker for as many application dependencies as possible. These notes sill have Python and Node installed locally, but no databases! On this M4 Pro chip Docker runs VERY fast 🙂
System Preferences
This is mostly a matter of personal preference but there are some important security steps here.
- Finder Settings
- General -> New Finder windows show -> set to home folder
- Sidebar -> Cleanup items in there, add home folder
- Advanced – Show all file extensions
- Advanced – When searching, search current folder
- iCloud
- Disable in my case “Save to iCloud” – shut off everything except iMessages
- Privacy & Security
- Enable location sharing only for system services (Find My Mac, etc)
- Enable FileVault (full disk encryption) – was enabled by default
- Network
- Firewall Enable Firewall, block all incoming connections
- CRAZY this is not on by default!
- Firewall Enable Firewall, block all incoming connections
- Lock Screen
- Require password after screen saver begins or display is turned off – Immediately
- Lock Screen Message: Property of Laurence Gellert?Please contact me at {phone}. IN CASE OF EMERGENCY – call {2nd contact}
- Mouse
- Uncheck scroll direction natural (I guess I’m weird in this one way?), speed up tracking speed, set secondary click right side
- Keyboard
- Disable the globe key from showing emojis
- Function keys
- Set F1, F2 as standard function keys
- Sounds
- Disable alert sounds, change alert volume to 2nd lowest
- Dock
- Auto hide dock, deselect show recent
- Cleanup Dock
- Remove most of the default programs, this is pretty tedious there is probably a better way to do this
- Display
- Configure Night Shift
- Menu bar
- Show bluetooth icon in menu bar
- Mission Control
- Hot Corners… disable all
- Screenshot preferences
- (cmd + shift +5), under options, deselect Show Floating Thumbnail
- Wallpaper
- Configure wall paper and screen saver to my liking
- Connect to external keyboard / mouse
- I’ve found the ProtoArc Backlit Bluetooth Keyboard and Mouse for Mac, KM100-A on Amazon is only $36 and works about as good the official Apple Magic Mouse + Keyboard which is 5x the price. The keys and clicks are quieter. Plus you can charge the mouse while using it. The only gesture I miss is horizontal scroll but that’s not a deal beaker.
Install Applications
- Chrome
- Settings -> Select You and Google > Sync and Google services.
- Toggle off the “Allow Chrome sign-in” option. I’m okay being signed into gmail.com through the web UI but I personally don’t want to be signed into Chrome itself.
- Firefox
- Import bookmarks into Safari, Chrome, FF
- AdBlock – Install an ad block plugin of your choice on Chrome and Firefox
- LibreOffice
- associate docx / xlxs files with LibreOffice (click on file and hit cmd + i to change association)
- Password manager of your choice
- iTerm2
- Updating setting so it exits after last window is closed
- Dark theme
- Sublime Text 4
- Fix Home/End key bindings: https://gist.github.com/ihor-lev/120e4c822d145f690f90a3fee77e2e53
- MS Teams
- Zoom
- Anti-virus – BitDefender is what I use
- Insomnia REST client
- Docker Desktop (which includes Docker CLI and Docker Compose)
- IntelliJ (for Apple Silicon)
- Manage Subscription and activate license using login
- Open Registry (Help -> Find Action -> Registry), change
- undo.documentUndoLimit to 1000
- undo.globalUndoLimit to 100
- Install plugins for Python, PHP, AWS, etc (react, markdown, etc already installed)
- Thunderbird – for local email
- Copy email to ~/email_thunderbird
- Start Thunderbird, but don’t import anything, then quit
- Edit ~/Library/Thunderbird/profiles.ini, put in the following then start it and select Default profile.
[Profile0] Name=default IsRelative=0 Path=/Users/{your user}/email_thunderbird/ Default=1 [General] StartWithLastProfile=1 Version=2 [Install{some hash value}] Default=/Users/{your user}/email_thunderbird/
- Setup VPNs as needed
- Setup peripherals – printers, scanners, etc
Developer tools
- GPG
- https://gpgtools.org/
- import existing keys via UI, edit and set to ultimate trust
- Try decrypting backups
- Remote desktop
- Import profiles, connect to each, set cert to trust
- Copy hosts file into place
- SSH
- copy files into .ssh folder
chmod 700 ~/.ssh chmod 600 ~/.ssh/* ssh-add -K ~/.ssh/{your_private_key}verify with ssh-add -L
make sure it comes back on reboot
- copy files into .ssh folder
- Cron – setup local cronjob – you may not need this but I have a few jobs that run periodically for backups, etc.
- crontab -e
- git
- install .gitconfig file in ~/
- brew plus common dependencies
- https://brew.sh/
Run the install command, then run the commands it tells you to at the end of the install script. - Then install these base packages (yours may vary)
brew install openssl readline sqlite3 xz zlib
- https://brew.sh/
- AWS CLI
- brew install awscli
copy in config and credentials files from backup
- brew install awscli
- OhMyZsh
- Install https://github.com/ohmyzsh/ohmyzsh
- enable plugins by editing ~/.zshrc
- plugins=(git) – was there by default
- set theme = lukerandall
- python + dependencies
- brew install pyenv pyenv-virtualenv
- Install whatever versions of python you need, and pick one as the default
- pyenv install 3.10.19
- pyenv install 3.12.12
- pyenv global 3.12.12
- To verify:
- restart terminal
- which python
- python -V
- pip –version
- Install virtualenv and virtualenvwrapper using the pip command tied to the pyenv
/Users/{user}/.pyenv/versions/3.12.12/bin/pip install virtualenv /Users/{user}/.pyenv/versions/3.12.12/bin/pip install virtualenvwrapper # To enable auto-activation add to .zshrc profile: export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init --path)" export WORKON_HOME=$HOME/.pyenv VIRTUALENVWRAPPER_PYTHON=/Users/{user}/.pyenv/versions/3.12.12/bin/python source /Users/{user}/.pyenv/versions/3.12.12/bin/virtualenvwrapper.sh export PYENV_VIRTUALENVWRAPPER_PREFER_PYVENV="true" if which pyenv > /dev/null; then eval "$(pyenv init -)"; fi eval "$(pyenv virtualenv-init -)"
- node / nvm
- brew install nvm
- follow instructions command it spits out
- mkdir ~/.nvm
- Add to the bottom of ~/.zshrcexport
- NVM_DIR=”$HOME/.nvm”
- [ -s “/opt/homebrew/opt/nvm/nvm.sh” ] && . “/opt/homebrew/opt/nvm/nvm.sh” # This loads nvm
- [ -s “/opt/homebrew/opt/nvm/etc/bash_completion.d/nvm” ] && . “/opt/homebrew/opt/nvm/etc/bash_completion.d/nvm” # This loads nvm bash_completion
- Restart shell
nvm -v # should work nvm install 18.17.1 nvm use 18.17.1 nvm alias default 18.17.1 node -v # should say 18.17.1