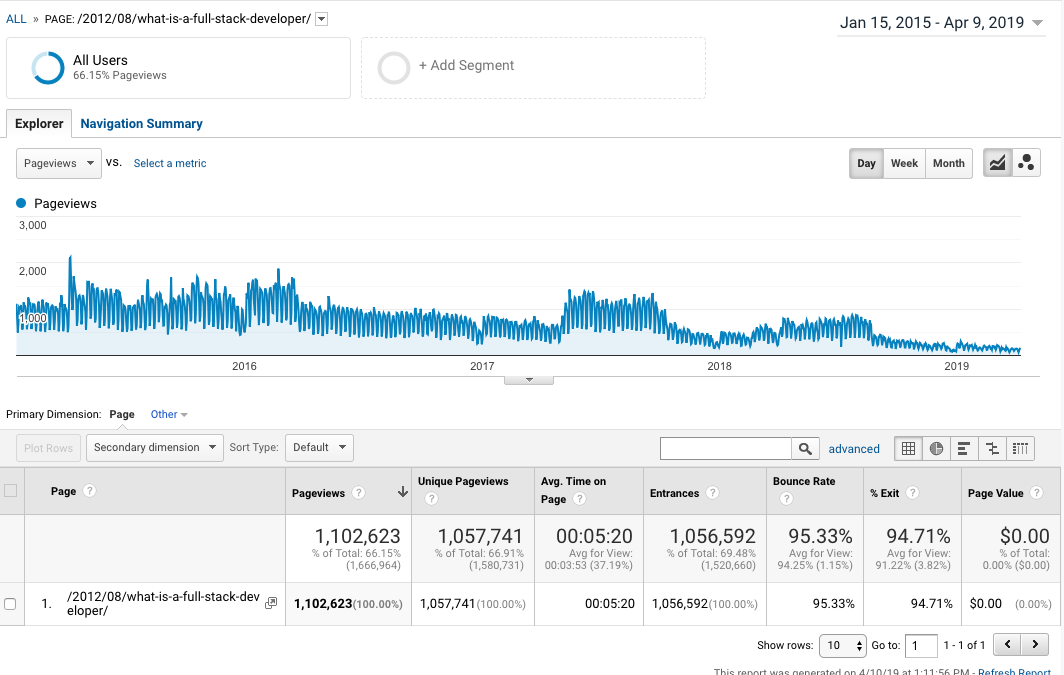
My opinion is very strong on this point – if you are using git, you should be using it on the command line.
Git is the best and most popular tool for doing source control. There used to be competitors, but why waste bytes listing them… Git was created by the infamous Linus Torvalds (the founder of Linux). Linus was fed up with everything else so he wrote his own tool to help him work on the Linux kernel more effectively.
Command Line vs GUI Tools for using git:
Git is a powerful tool. As a software developer you need to understand what git is doing. GUI tools are just wrappers over the command line tool and they hide or simplify the details which is bad. I’ve found GUI tools are a) slow, b) sometimes screw up merges, and c) sometimes make branches from a starting point you didn’t want.
In other words git GUI tools are more trouble than they are worth. For beginning developers, my thinking is, you should understand how to use git via command line so you know what the GUI tool is doing under the hood (and then uninstall the GUI tool).
Besides, it only takes a few minutes to learn the basics of git command line. If you use it everyday you’ll get good at it pretty quick! This translates into having more confidence on the command line, which is great for many other reasons.
On Mac or Linux, your terminal is built in. On Windows, install the git bundle, then you can right click on any folder and go to “Git Bash Here” which will get you a DOS prompt with the proper paths and environment variables setup.
The exception to my command line focused dogma is when I review commits from other team members or look back through my own commit history. For that I use the github (or bitbucket) web interface and not the command line. When looking at code changes it really helps to have a visual diff with the red/green colored lines. It also helps for collaboration to be able to comment on the commit or even a specific line of code.
The top git commands I use:
- Checkout a repo:
git clone {url to repo}
- Working on code:
git diff(see what I changed)git add [files](stage files for commit)git diff --cached(shows me the changes I’m about to commit, I always do this as a final personal code review before committing)git commit -m "A useful message"(see my post on writing a proper commit message)- If I screwed up the commit, I can do
git commit --amendto change the message or contents of the commit. git push(send it to the remote repo for all to see, at this point, going back can still be done with the force flag-fbut use with caution because if another developer pulled your change it gets very messy)
- Undoing changes:
git checkout [files](note this will erase local changes from your system, reverting files to the last commit. This is useful if you went down a rat hole, or accidentally broke something.)git reset HEAD [files](this will unstage files from the next commit, useful if you accidentally added a file and need to move it back down to the list of files that won’t be committed. This leaves changes in tact.)- If your repo is hopelessly screwed up, you can always clone a fresh repo with
git clone {url to repo}. Beforehand, take a backup of the folder your broken repo lives in just in case you need something in there.
- Get code pushed by my team members:
git pull(I use an aliasgit pl, see my .gitconfig below, which does a rebase and recurses any submodules. This way my commits are moved after any incoming commits which avoids annoying merges on pull.)
- Viewing commit history:
git log(shows a lot of commits on your current branch, can be useful as a sanity check)- Again, I use github / bitbucket to view history, but the command line tool has a rich set of tools in this area tool that I don’t use much. The aliases below can be helpful
git landgit lg.
- Make a new feature branch and push it to the remote repo:
git checkout {branch I want to start from}(typically master, but could be a feature branch)git pull(make sure I’m up to date on the starting branch)git checkout -b {new_branch_name}(create my new branch)git push -u origin {new_branch_name}(push my new branch to the remote repo, initially with no changes)
- Changing between branches:
- As a developer you’ll be working on several things at a time, which means several open branches. Here is how I switch branches:
- 1) Disable any background severs / processes like npm, grunt, gulp, react, angular, etc. If you have a front end watch script, or a javascript build process running when you switch branches it will get really confused.
- 2) Make sure your checkout is clean (no pending changes) using
git st - 3)
git checkout {branch_name}(switch to the branch)
- Other cool commands:
git rebase {source_branch}(integrate changes from source branch into current branch, and replay commits on feature branch. This is the secret to fixing merge conflicts before a merge!)git cherry-pick {commit hash}(pull in a single commit from another branch, can be a life saver if you need just one commit but not the whole branch)
Related to git command line is your .gitconfig file, which lives in your home folder. It has many powerful options, but the one I want to show you is the [alias] section. These are shortcut commands that make git command line much easier to use. I can’t take credit for any of these, I cobbled them together from various other developers / blog posts along the way.
[alias]
st = status
c = commit
co = checkout
br = branch
tg = tag -a
df = diff
dfc = "diff --cached"
dt = difftool
lg = "log -p"
l = "log --pretty=oneline"
pl = "pull --rebase --recurse-submodules"
ph = push
phf = "push -f"
brls = "branch -a"
tgls = "tag --list"
stls = "stash list"
chp = "cherry-pick"
ch = "cherry -v"
chh = "cherry -v HEAD"
subup = "submodule update"
subst = "submodule status"
cl = "clone --recursive"
notmerged = "branch --no-merged"
graph = "log --oneline --graph"
With these aliases, git diff --cached becomes git dfc, or git commit becomes git c which saves a few keystrokes every day.
The graph alias above is very cool if you have a project with commit history and branches.
Here are some additional resources for learning git.
Let me know if I missed something and I’ll add it here and give you props.